
Summary
Optimizing crawl budgets yields significant benefits: 20%-40% faster indexing for fresh content, a 50% boost in crawl efficiency by focusing on high-value pages, and a 15%-30% increase in organic traffic. Additionally, it reduces server loads by 25%-50% and enhances regional search performance by 10%-20% with hreflang tags.
Crawl budget is an important SEO concept, especially for large websites with millions of pages or medium-sized sites with thousands of pages that are updated daily.
For instance, a site like eBay.com represents a platform with millions of pages, while websites such as Gamespot.com, featuring frequently updated user reviews and ratings, fall into the category of medium-sized sites with high update frequency.
What Is Crawl Budget?
Crawl budget is the number of pages that search engine bots, like Googlebot, crawl on your website within a specific timeframe.
Several factors influence crawl budget, including maintaining a balance between Googlebot’s efforts to avoid overloading your server and Google’s goal to effectively crawl your site.
Optimizing crawl budget involves implementing strategies to improve efficiency and ensure search engine bots can crawl your pages more effectively and frequently.
Why Is Crawl Budget Optimization Important?
Crawling is the essential first step for your content to appear in search results. Without being crawled, new pages or updates won’t make it into search engine indexes.
Frequent crawler visits ensure that updates and new pages are indexed quickly. This speeds up the impact of your optimization efforts, helping improve rankings faster.
With Google’s ever-growing index of billions of pages, crawling each URL comes with computational and storage costs. As the web expands, search engines are aiming to manage these costs by reducing crawl rates and indexation.
Additionally, Google is committed to sustainability and reducing carbon emissions, which influences how crawling resources are allocated.
For small websites with just a few hundred pages, crawl budget may not be a concern. However, for large websites, efficient resource management becomes crucial. Optimizing your crawl budget ensures Google can crawl your website effectively while minimizing resource usage.
Now, let’s explore strategies to optimize your crawl budget in today’s evolving digital landscape.
1. Disallow Crawling of Action URLs in Robots.txt
Google has confirmed that disallowing URLs in the robots.txt file doesn’t directly affect your crawl budget. The crawling rate remains unchanged. So why is this practice important?
By disallowing unimportant URLs, you can guide Google to prioritize crawling the more valuable sections of your website.
For example, internal search features with query parameters like / ?q=google or e-commerce filter facets like / ?color=red&size=s can generate an infinite number of unique URL combinations. These URLs often don’t contain unique content and are primarily for user convenience—not for search engines.
Allowing Googlebot to crawl such URLs wastes crawl budget and reduces overall crawl efficiency. Blocking these URLs via robots.txt ensures Google focuses its crawl efforts on meaningful pages.
Example Robots.txt Rules:
Here’s how you can block internal search, filter facets, or query strings:
Disallow: *?*s=*
Disallow: *?*color=*
Disallow: *?*size=*
Breakdown of the Syntax:
*(asterisk): Matches any sequence of characters (including none).
?(question mark): Marks the start of a query string.
=*(equals sign + asterisk): Matches the=sign followed by any characters.
These rules ensure that URLs containing specific query parameters are excluded from being crawled by search engines.
Important Considerations:
While effective, this approach can lead to unintended disallowing of URLs. For instance, blocking *?*s=* might also block / ?pages=2 because ?pages= contains the s parameter.
To avoid such issues, carefully review your rules to ensure you’re not unintentionally disallowing important URLs. This strategy helps optimize crawl efficiency while keeping your website accessible to search engines.
If you want to disallow URLs with a specific single character, you can use a combination of rules:
To optimize your robots.txt file for specific parameters:
Disallow: *?s=*
Disallow: *&s=*
This adjustment targets exact query parameters like ?s= or &s= without using an asterisk (*) between the ? and s characters, requiring manual addition for each variation.
For example, if your site generates URLs like ?add_to_wishlist=1, use:
Disallow: /*?*add_to_wishlist=*This is a straightforward and essential first step, as recommended by Google.
For example, blocking unnecessary parameters in your robots.txt file can significantly reduce the crawling of pages with query strings. In one case, Google attempted to crawl tens of thousands of URLs with various parameter values that were irrelevant, leading to non-existent pages. Blocking these parameters prevented wasted crawl resources and improved efficiency.
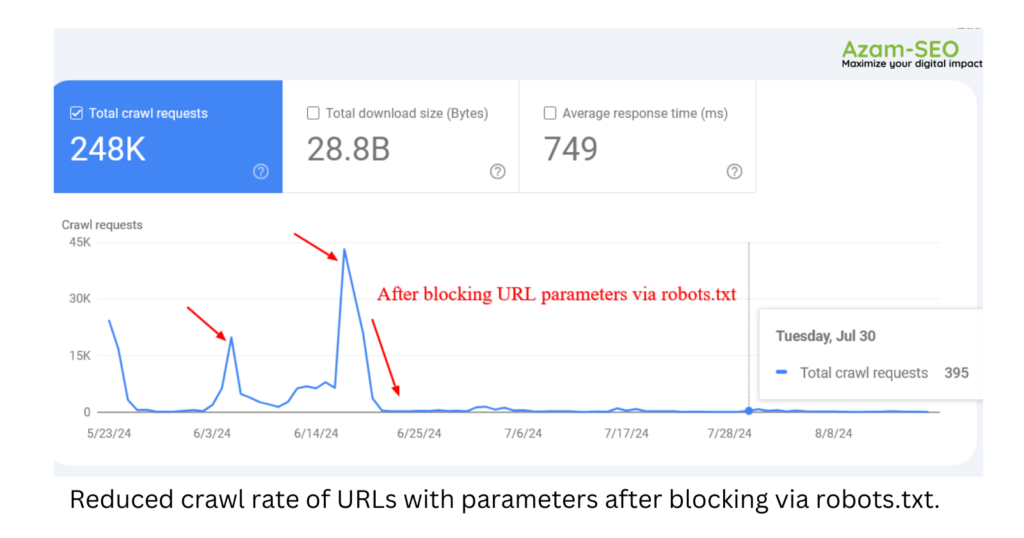
However, there are instances where disallowed URLs may still be crawled and indexed by search engines. While this might seem unusual, it’s typically not a major concern. This often occurs when other websites link to those URLs, giving search engines a reason to process them.
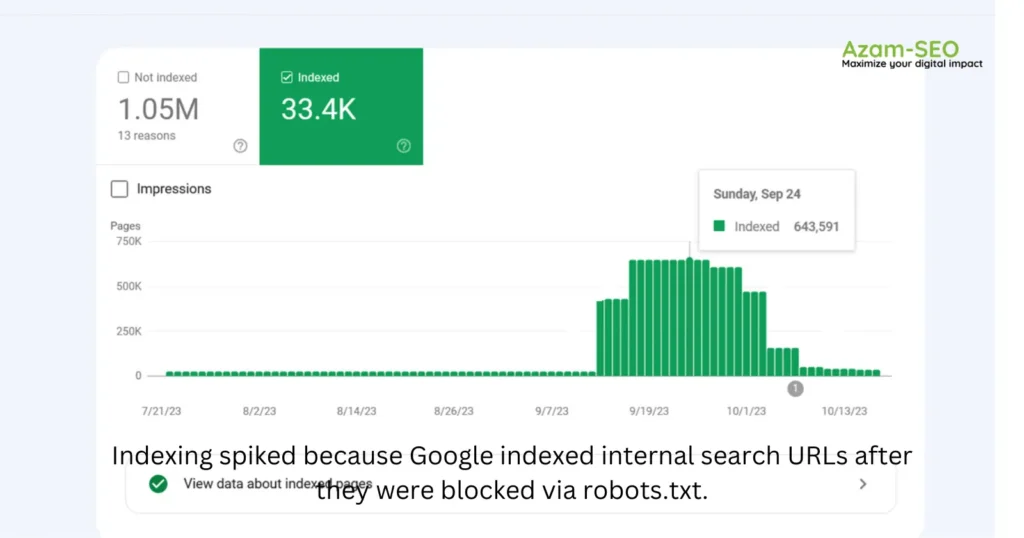
Google confirmed that the crawling activity will drop over time in these cases.

Google’s comment on Reddit, July 2024
1.2. Block Unnecessary Resource URLs in Robots.txt
In addition to blocking action URLs, you might want to block JavaScript files that are not essential for the website’s layout or rendering.
For instance, if you have JavaScript files responsible for opening images in a popup when users click on them, you can block them in robots.txt to prevent Google from wasting crawl budget on them.
Here’s an example of how to block a JavaScript file:
Disallow: /assets/js/popup.js
However, avoid blocking resources critical for rendering. For example, if your content is dynamically loaded using JavaScript, Google needs access to these JS files to index the content they load.
Similarly, consider REST API endpoints for form submissions. For instance, if you have a form with an action URL like “/rest-api/form-submissions/”, don’t block it.
Google may potentially crawl these URLs, but since they aren’t related to rendering, it’s advisable to block them.
Disallow: /rest-api/form-submissions/
However, keep in mind that headless CMSs often rely on REST APIs to dynamically load content, so ensure you don’t block those crucial endpoints.
In summary, review the resources that aren’t tied to rendering and block them accordingly.
2. Beware of Redirect Chains
Redirect chains happen when multiple URLs lead to other URLs, which in turn redirect again. If this process continues too long, crawlers might abandon the chain before reaching the final destination.
For example, URL 1 redirects to URL 2, which redirects to URL 3, and so on. Chains can also lead to infinite loops when URLs redirect to each other.
Avoiding redirect chains is a basic step in maintaining website health.
Ideally, you should aim to eliminate all redirect chains across your entire domain. However, for larger websites, this may be an impossible task. 301 and 302 redirects are inevitable, and you can’t control redirects from external sites linking to yours.
A few redirects here and there generally won’t cause significant issues, but long chains and loops can be problematic.
To troubleshoot redirect chains, use SEO tools like Screaming Frog, Lumar, or Oncrawl.
When you find a redirect chain, the best way to resolve it is by eliminating all intermediate URLs between the first and final page. For example, if the chain passes through seven pages, redirect the first URL straight to the seventh.
Another effective approach is to replace internal URLs that cause redirects with their final destination URLs within your CMS.
Depending on your CMS, different solutions may be available. For example, you can use a specific plugin for WordPress. For other CMSs, you may need a custom solution or assistance from your development team.
Opt for Server-Side Rendering (HTML) Whenever Possible
Google’s crawler uses the latest version of Chrome and can effectively render content loaded by JavaScript.
However, it’s important to consider the implications. Googlebot crawls a page, processes resources like JavaScript, and then expends additional computational resources to render them.
Since computational costs are significant for Google, it aims to minimize them as much as possible.
So, why add extra processing for Googlebot by using client-side JavaScript to render content?
For this reason, it’s best to use HTML for rendering whenever possible. This approach ensures you’re not adding unnecessary burdens on any crawler, improving your chances of successful crawling.
3. Opt for Server-Side Rendering (HTML) Whenever Possible
Google’s crawler uses the latest version of Chrome and can effectively render content loaded by JavaScript.
However, it’s important to consider the implications. Googlebot crawls a page, processes resources like JavaScript, and then expends additional computational resources to render them.
Since computational costs are significant for Google, it aims to minimize them as much as possible.
So, why add extra processing for Googlebot by using client-side JavaScript to render content?
For this reason, it’s best to use HTML for rendering whenever possible. This approach ensures you’re not adding unnecessary burdens on any crawler, improving your chances of successful crawling.
4. Enhance Page Speed
As mentioned earlier, Googlebot crawls and renders pages using JavaScript. The faster it can render webpages with fewer resources, the easier it is for Google to crawl your site. This largely depends on how well-optimized your website’s speed is.
Google says:
Google’s crawling is limited by bandwidth, time, and availability of Googlebot instances. If your server responds to requests quicker, we might be able to crawl more pages on your site.
Using server-side rendering is already a significant step in improving page speed. However, it’s also crucial to optimize your Core Web Vitals metrics, with a particular focus on server response time. This ensures that your pages load efficiently, further enhancing your site’s performance and crawlability.
5. Manage Your Internal Links Carefully
Google crawls URLs found on your pages, and it’s important to remember that crawlers treat each URL as a separate page.
If your website uses the ‘www’ version, ensure that your internal URLs, especially those in navigation, point to the canonical version (e.g., with ‘www’), and do the same for the non-www version.
Another common issue is missing trailing slashes. If your URLs include a trailing slash, make sure your internal links do as well. Otherwise, unnecessary redirects, like “https://www.example.com/sample-page” to “https://www.example.com/sample-page/“, will cause multiple crawls per URL.
Additionally, avoid broken internal links and soft 404 pages, as they waste crawl budget and harm user experience.
To address these issues, using a website audit tool is highly recommended. Tools like WebSite Auditor, Screaming Frog, Lumar, Oncrawl, and SE Ranking are great options for auditing your site.
6. Keep Your Sitemap Updated
Maintaining an up-to-date XML sitemap is a smart move for improving crawlability.
It helps bots easily understand the structure of your site and where internal links lead.
Ensure that only canonical URLs are included in your sitemap, and make sure it aligns with the latest version of your robots.txt file.
Additionally, ensure that your sitemap loads quickly to enhance crawling efficiency.
7. Use the 304 Status Code
When Googlebot crawls a URL, it sends a date through the “If-Modified-Since” header, indicating the last time it crawled that URL.
If your webpage hasn’t changed since that date, you can return a “304 Not Modified” status code with no response body. This informs search engines that the content hasn’t been updated, allowing Googlebot to use the previously cached version from its last visit.
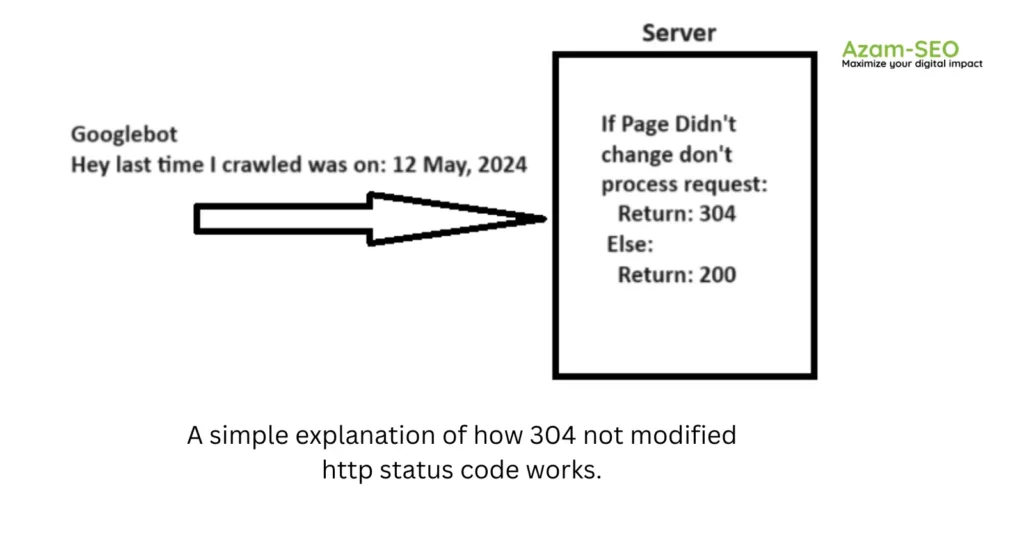
Imagine how much server resource savings you could achieve, while also helping Googlebot conserve its resources, especially when dealing with millions of webpages. The impact can be substantial.
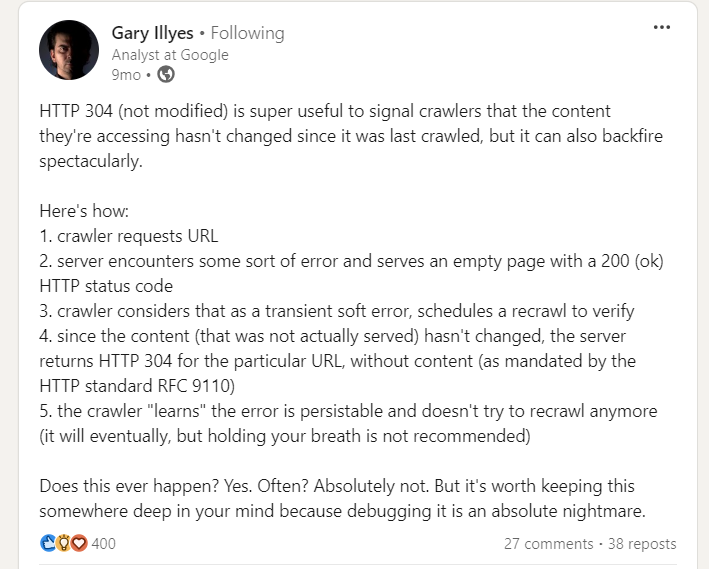
Gary Illes on LinkedIn
So, it’s important to be cautious. If your server mistakenly serves empty pages with a 200 status code, it can cause crawlers to stop recrawling those pages, potentially leading to long-term indexing issues.
8. Hreflang Tags Are Crucial
To help crawlers analyze your localized pages, it’s essential to use hreflang tags. Clearly indicate to Google the different localized versions of your pages.
Start by including the <link rel="alternate" hreflang="lang_code" href="url_of_page" /> tag in your page’s header, where “lang_code” is the language code for the supported language.
Additionally, use the <loc> element for each URL to point to the localized versions of your pages. This helps ensure proper indexing and targeting for different regions and languages.
9. Ongoing Monitoring and Maintenance
Regularly review your server logs and the Crawl Stats report in Google Search Console to track crawl anomalies and detect potential issues.
If you observe periodic spikes in 404 errors, it’s often due to infinite crawl spaces (as discussed earlier) or other underlying problems your website might be facing.

Often, it’s helpful to combine server log data with Search Console information to pinpoint the root cause of crawl issues. This combined approach gives you a clearer understanding of what might be affecting your site’s crawlability.
I am a Certified SEO Professional and freelance article writer with years of hands-on experience in SEO and content creation. A Bachelor of Science in Marketing graduate (2012), I specialize in helping businesses grow by staying updated with the latest industry trends. Passionate about solving challenges, I deliver results-driven strategies tailored to client success .

